

Introduction:
Data lakes have become pivotal in managing and analyzing large volumes of data. As organizations scale, the architecture of these data lakes evolves to meet growing demands for efficiency, flexibility, and governance. This blog will explore three key data lake patterns: Central Data Lake Architecture, Central Storage with Distributed Compute, and Decentralized Data Mesh Architecture. Each pattern offers unique benefits and challenges, and understanding these can help organizations choose the best approach for their needs.
1. Central Data Lake Architecture with Central Storage, Compute, and Catalog/Governance
Overview: This traditional data lake architecture involves a dedicated data lake team responsible for creating, managing, and maintaining all aspects of the data lake, including data pipelines, storage, access control, reports, and dashboards.
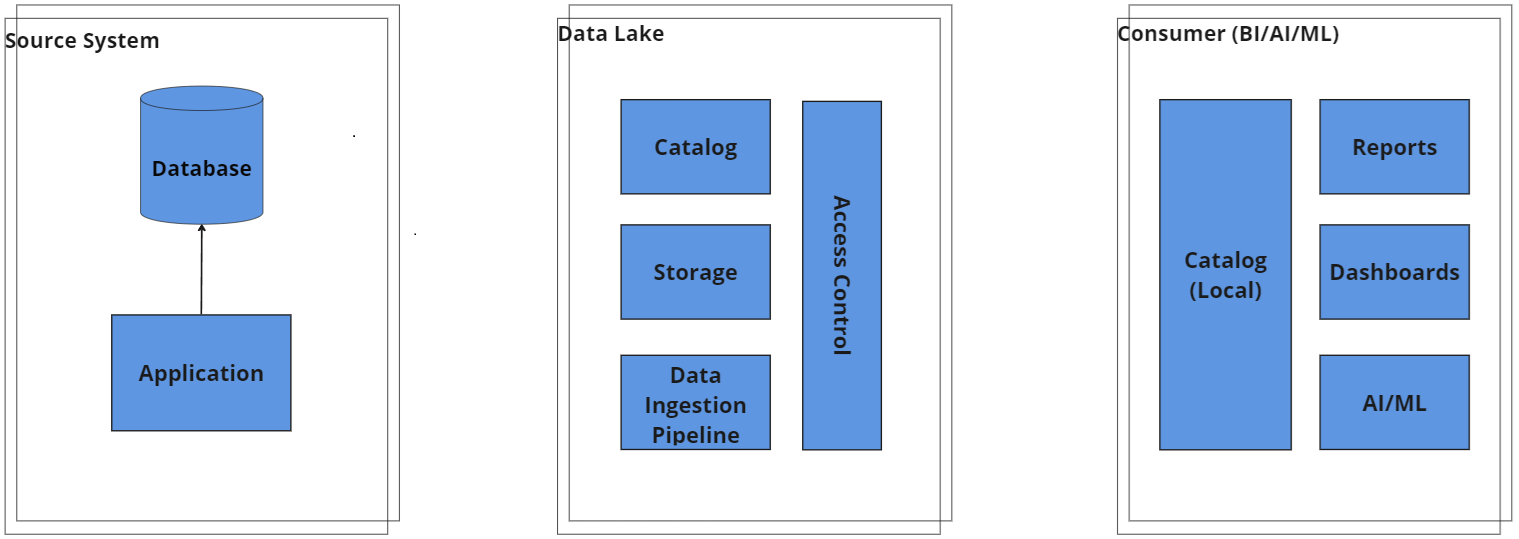
Key Features:
- Centralized management of all data lake components.
- Single team ownership of data, storage, compute, and governance.
- High dependency on the data lake team for all data needs.
Benefits:
- Simplified management with a single point of control.
- Consistent governance and security policies.
Challenges:
- Heavy dependency on the central team, leading to potential bottlenecks.
- High operational costs managed by one team.
Use Cases:
- Organizations with a dedicated data team capable of handling large-scale operations.
- Environments where uniform governance and control are critical.
2. Central Data Lake Architecture with Central Storage and Catalog/Governance and Distributed Compute
Overview: A variation of the traditional architecture, this pattern decentralizes the data pipelines, allowing line of business (LOB) accounts to operate them. The central data lake team still manages data storage costs and governance.
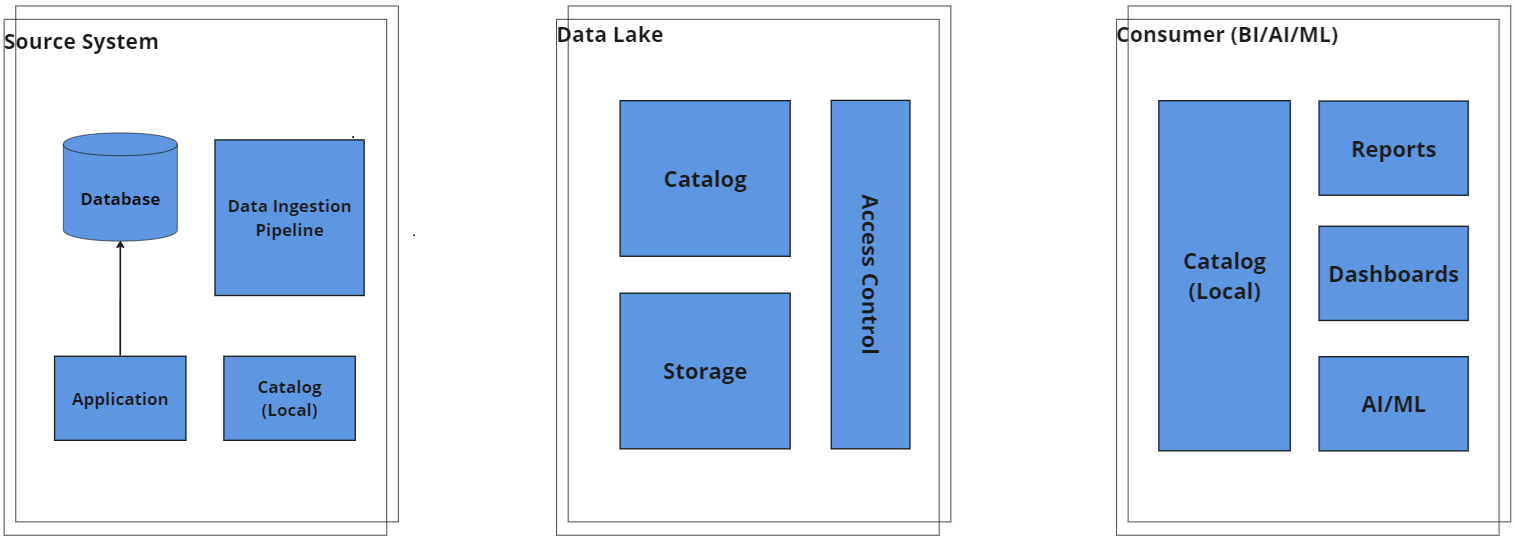
Key Features:
- Centralized storage and governance.
- Distributed data pipeline operations managed by LOB accounts.
Benefits:
- Reduces bottlenecks by decentralizing data pipeline management.
- Clear cost ownership for LOB accounts, promoting accountability.
Challenges:
- Requires coordination between central and LOB teams.
- Potential complexity in managing distributed pipelines.
Use Cases:
- Organizations looking to distribute operational responsibilities while maintaining centralized governance.
- Environments where cost management and accountability are crucial.
3. De-centralized Data Lake Architecture with Central Catalog/Governance and Distributed Storage and Compute (Data Mesh Architecture)
Overview: In a data mesh architecture, data producers (LOBs) retain ownership of their data, including pipelines, compute, and storage costs. The central team governs the catalog and access control, allowing data to be published as a product for the organization.
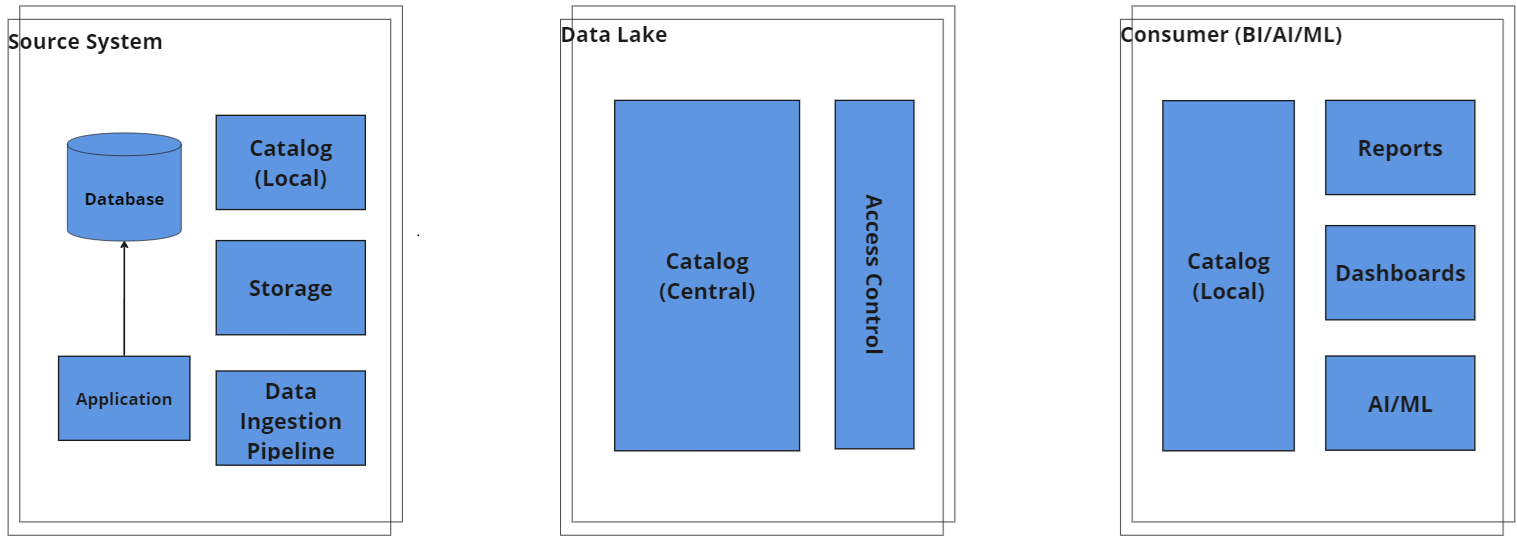
Key Features:
- Decentralized data ownership and management.
- Centralized catalog and access control for published data.
- Data treated as a product, available to the entire organization.
Benefits:
- Promotes data ownership and accountability within LOBs.
- Enhances scalability by distributing data management.
- Facilitates data sharing across the organization.
Challenges:
- Requires robust governance to ensure data quality and consistency.
- Potential for increased complexity in managing multiple data sources.
Use Cases:
- Large organizations with multiple independent data-producing teams.
- Environments prioritizing scalability and flexibility in data management.
Conclusion:
Choosing the right data lake architecture depends on an organization’s specific needs and goals. Centralized architectures offer simplicity and uniform control, while decentralized approaches like data mesh promote scalability and flexibility. By understanding the benefits and challenges of each pattern, organizations can make informed decisions to optimize their data management strategies.
Feedback and Discussion: We’d love to hear your thoughts and experiences with these data lake architectures. What challenges have you faced, and how did you overcome them? Share your insights and join the discussion in the comments below!